Biography
I am currently a Tenure-Track Assistant Professor at Brown University, School of Engineering. I obtained my Ph.D. in Computer Science from University of California, Los Angeles in 2019 supervised by Prof. Jason Cong, who leads UCLA VAST (VLSI Architecture, Synthesis and Technology) Group and CDSC (The Center for Domain-Specific Computing). My major interest is in Customized Computer Architecture and Programming Abstraction for Applications including Healthcare, e.g., Precision Medicine and Artificial Intelligence. I’m honored to receive “Outstanding Recognition in Research” from UCLA Samueli School of Engineering in 2019. I have also received 🏆 2019 TCAD Donald O. Pederson Best Paper Award 🏆 in recognition of best paper published in the IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems (TCAD) in the two calendar years preceding the award. My papers have also received 🏆 2024 IEEE IGSC Best Viewpoint Paper 🏆, 2025 ACM/SIGDA FPGA Best Paper Nominee 🏆, 2018 IEEE/ACM ICCAD Best Paper Nominee 🏆, 2018 IEEE ISPASS Best Paper Nominee 🏆.
I’m actively recruiting PhD students and research interns! Self-motivated students with relevant research and project experience (compiler, GPU and FPGA programming, artificial intelligence algorithm and application development, etc.) are highly encouraged to contact me via email.
Download my CV.
Website at Brown
Researchers@Brown
Former Website at UCLA
- Application & Algorithm: Artificial Intelligence, Healthcare
- Abstraction: Programming, Modeling and Optimization
- Architecture: Heterogeneous Computing with FPGA, GPU, ASIC, NPU
-
PhD in Computer Science, 2019
University of California, Los Angeles
-
MSc in Electrical Engineering, 2014
University of California, Los Angeles
-
BSc in Electrical Engineering, 2012
Southeast University, Chien-Shiung Wu Honor College
Research Focus
Health & Artificial Intelligence
Software
Hardware
Experience
Responsibilities include:
- Tenure-Track Assistant Professor
- Computer Engineering Concentration Advisor
Responsibilities include:
- Tenure-Track Assistant Professor
Responsibilities include:
- High-Performance Convolution Neural Network Library for Deep Learning ASIC Acclerator
- Pre-silicon Architecture Exploration and Performance Modeling
- Post-silicon ASIC Bring-Up and System Software Optimization
Responsibilities include:
- Resource allocation and scheduling optimization for Genome Analysis Toolkit(GATK4) in the cloud.
- Cost-Optimal heterogeneous computing by orchestrating seas of datacenter scale resources including computing (CPUs+GPU+FPGA accelerators), storage (HDD, SSD, local disk)
Responsibilities include:
- Developed a scalable end-to-end tool to generate >2M grammar fixed (preposition, article and etc.) sentences from Wikipedia.
- Implemented LSTM-based neural network model for translation tasks
Responsibilities include:
- Implemented image compression algorithm in C++(software reference code) and also implemented hardware accelerator on FPGA
Honors
Recent Posts

Projects
Recent & Upcoming Talks


Featured Publications
Deep neural network (DNN) models are increasingly deployed in real-time, safety-critical systems such as autonomous vehicles, driving the need for specialized AI accelerators. However, most existing accelerators support only non-preemptive execution or limited preemptive scheduling at the coarse granularity of DNN layers. This restriction leads to frequent priority inversion due to the scarcity of preemption points, resulting in unpredictable execution behavior and, ultimately, system failure.
To address these limitations and improve the real-time performance of AI accelerators, we propose DERCA, a novel accelerator architecture that supports fine-grained, intra-layer flexible preemptive scheduling with cycle-level determinism. DERCA incorporates an on-chip Earliest Deadline First (EDF) scheduler to reduce both scheduling latency and variance, along with a customized dataflow design that enables intra-layer preemption points (PPs) while minimizing the overhead associated with preemption. Leveraging the limited preemptive task model, we perform a comprehensive predictability analysis of DERCA, enabling formal schedulability analysis and optimized placement of preemption points within the constraints of limited preemptive scheduling. We implement DERCA on the AMD ACAP VCK190 reconfigurable platform. Experimental results show that DERCA outperforms state-of-the-art designs using non-preemptive and layer-wise preemptive dataflows, with less than 5% overhead in worst-case execution time (WCET) and only 6% additional resource utilization. DERCA is open-sourced on GitHub: https://github.com/arc-research-lab/DERCA.
As AI continues to grow, modern applications are becoming more data- and compute-intensive, driving the development of specialized AI chips to meet these demands. One example is AMD’s AI Engine (AIE), a dedicated hardware system that includes a 2D array of high-frequency very-long instruction words (VLIW) vector processors to provide high computational throughput and reconfigurability. However, AIE’s specialized architecture presents tremendous challenges in programming and compiler optimization. Existing AIE programming frameworks lack a clean abstraction to represent multi-level parallelism in AIE; programmers have to figure out the parallelism within a kernel, manually do the partition, and assign sub-tasks to different AIE cores to exploit parallelism. These significantly lower the programming productivity. Furthermore, some AIE architectures include FPGAs to provide extra flexibility, but there is no unified intermediate representation (IR) that captures these architectural differences. As a result, existing compilers can only optimize the AIE portions of the code, overlooking potential FPGA bottlenecks and leading to suboptimal performance.
To address these limitations, we introduce ARIES, an agile multilevel intermediate representation (MLIR) based compilation flow for reconfigurable devices with AIEs. ARIES introduces a novel programming model that allows users to map kernels to separate AIE cores, exploiting task- and tile-level parallelism without restructuring code. It also includes a declarative scheduling interface to explore instruction-level parallelism within each core. At the IR level, we propose a unified MLIR-based representation for AIE architectures, both with or without FPGA, facilitating holistic optimization and better portability across AIE device families. For the General Matrix Multiply (GEMM) benchmark, ARIES achieves 4.92 TFLOPS, 15.86 TOPS, and 45.94 TOPS throughput under FP32, INT16, and, INT8 data types on Versal VCK190 respectively. Compared with the state-of-the-art (SOTA) work CHARM for AIE, ARIES improves the throughput by 1.17x, 1.59x, and 1.47x correspondingly. For ResNet residual layer, ARIES achieves up to 22.58x speedup compared with optimized SOTA work Riallto on Ryzen-AI NPU. ARIES is opensourced on GitHub: https://github.com/arc-research-lab/Aries.

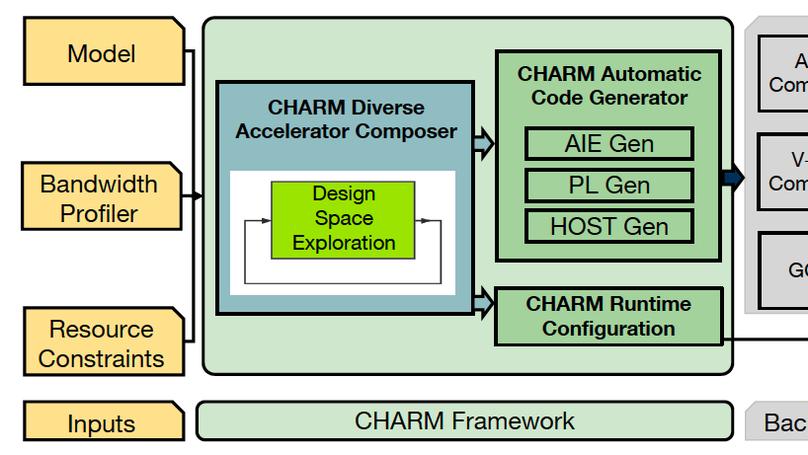
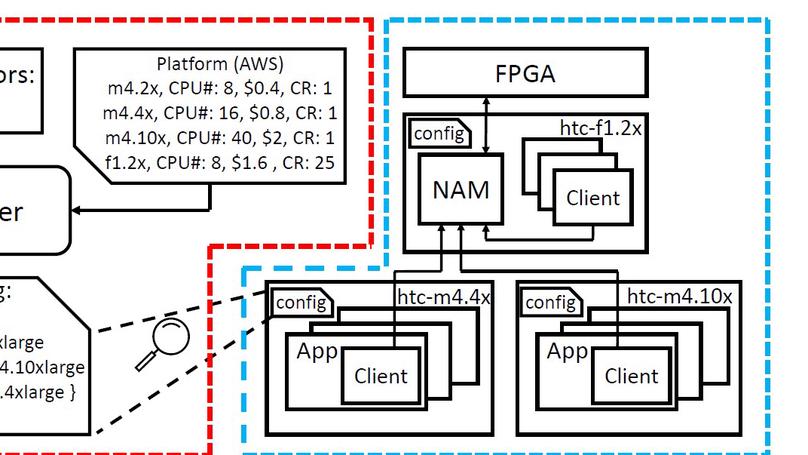
Recent Publications
Contact
- peipei_zhou AT brown.edu
- 184 Hope St, Providence, RI 02912