CHARM: Composing Heterogeneous AcceleRators for Matrix Multiply on Versal ACAP Architecture (🔥📣New Paper & Project🔥📣! )
Abstract
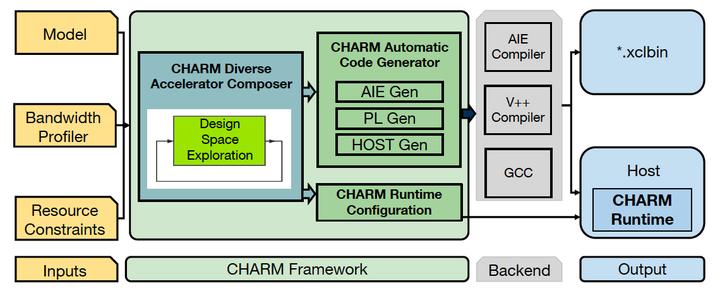
Dense matrix multiply (MM) serves as one of the most heavily used kernels in deep learning applications. To cope with the high computation demands of these applications, heterogeneous architectures featuring both FPGA and dedicated ASIC accelerators have emerged as promising platforms. For example, the AMD/Xilinx Versal ACAP architecture combines general-purpose CPU cores and programmable logic (PL) with AI Engine processors (AIE) optimized for AI/ML. An array of 400 AI Engine processors executing at 1 GHz can theoretically provide up to 6.4 TFLOPs performance for 32-bit floating-point (fp32) data. However, machine learning models often contain both large and small MM operations. While large MM operations can be parallelized efficiently across many cores, small MM operations typically cannot. In our investigation, we observe that executing some small MM layers from the BERT natural language processing model on a large, monolithic MM accelerator in Versal ACAP achieved less than 5% of the theoretical peak performance. Therefore, one key question arises, how can we design accelerators to fully use the abundant computation resources under limited communication bandwidth for end-to-end applications with multiple MM layers of diverse sizes? We identify the biggest system throughput bottleneck resulting from the mismatch of massive computation resources of one monolithic accelerator and the various MM layers of small sizes in the application. To resolve this problem, we propose the CHARM framework to compose multiple diverse MM accelerator architectures working concurrently towards different layers within one application. CHARM includes analytical models which guide design space exploration to determine accelerator partitions and layer scheduling. To facilitate the system designs, CHARM automatically generates code, enabling thorough onboard design verification. We deploy the CHARM framework for four different deep learning applications, including BERT, ViT, NCF, MLP, on the AMD/Xilinx Versal ACAP VCK190 evaluation board. Our experiments show that we achieve 1.46 TFLOPs, 1.61 TFLOPs, 1.74 TFLOPs, and 2.94 TFLOPs inference throughput for BERT, ViT, NCF, MLP, respectively, which obtain 5.40x, 32.51x, 1.00x and 1.00x throughput gains compared to one monolithic accelerator.
Peipei Zhou
Assistant Professor of Engineering
My research interests include Customized Computer Architecture and Programming Abstraction for Health & AI Applications