Abstract
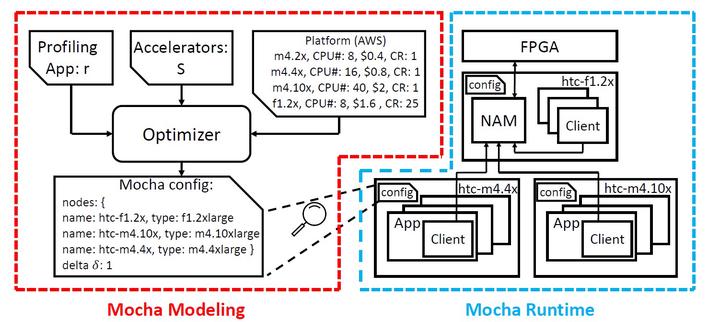
FPGAs have been widely deployed in public clouds, e.g., Amazon Web Services (AWS) and Huawei Cloud. However, simply offloading accelerated kernels from CPU hosts to PCIe-based FPGAs does not guarantee out-of-pocket cost savings in a pay-as-you-go public cloud. Taking Genome Analysis Toolkit (GATK) applications as case studies, although the adoption of FPGAs reduces the overall execution time, it introduces 2.56× extra cost, due to insufficient application-level speedup by Amdahl’s law. To optimize the out-of-pocket cost while keeping high speedup and throughput, we propose Mocha framework as a distributed runtime system to fully utilize the accelerator resource by accelerator sharing and CPU-FPGA partial task offloading. Evaluation results on HaplotypeCaller (HTC) and Mutect2 in GATK show that on AWS, Mocha saves on the application cost by 2.82x for HTC, 1.06x for Mutect2 and on Huawei Cloud by 1.22x, 1.52x respectively than straightforward CPU-FPGA integration solution with less than 5.1% performance overhead.
Peipei Zhou
Assistant Professor of Engineering
My research interests include Customized Computer Architecture and Programming Abstraction for Health & AI Applications